嵟嬤偺榖戣 2012擭7寧21擔
侾丏GPU僗僷僐儞偺幚傾僾儕働乕僔儑儞惈擻
丂丂2012擭7寧18擔偺HPCWire偑丆GPU傾僋僙儔儗乕僞傪晅偗偨応崌偺惈擻岦忋偵偮偄偰曬偠偰偄傑偡丅3寧偺Accelerated Computational Science Symposium偱偺敪昞偲偺偙偲偱丆偦傟傎偳嵟嬤偺僯儏乕僗偱偼側偄偺偱偡偑丆嫽枴怺偄偺偱徯夘偟傑偡丅
丂丂GPU柍偺僔僗僥儉偼Swiss National Supercomputing Center偺Monterosa偲偄偆CRAY XE6僔僗僥儉偱丆奺僲乕僪偼AMD偺Interlagos偑2僜働僢僩偲偄偆峔惉偱偡丅堦曽丆GPU晅偼ORNL偺TitanDev僔僗僥儉偱丆奺僲乕僪偼丆Interlagos 1僠僢僾偲NVIDIA偺Fermi GPU偑晅偄偰偄傑偡丅
丂丂11庬偺幚梡傾僾儕働乕僔儑儞傪丆偦傟偧傟偵僠儏乕僯儞僌偟偨宍偱丆惈擻傪斾妑偟偨偺偑師偺昞偱偡丅
| Application | Performance | Software Framework |
| 丂 | ||
| XK6 vs XE6 | ||
| S3D | 1.4 | OpenACC |
| 丂 | ||
| Turbulent combustion | ||
| NAMD | 1.4 | CUDA |
| 丂 | ||
| Molecular dynamics | ||
| CP2K | 1.5 | CUDA |
| 丂 | ||
| Chemical physics | ||
| CAM-SE | 1.5 | PGI CUDA Fortran |
| 丂 | ||
| Community atmosphere model | ||
| WL-LSMS | 1.6 | CUDA |
| 丂 | ||
| Statistical mechanics of magnetic materials | ||
| GTC/GTC-GPU | 1.6 | CUDA |
| 丂 | ||
| Plasma physics for fusion energy | ||
| SPECFEM-3D | 2.5 | CUDA |
| 丂 | ||
| Seismology | ||
| QMCPACK | 3.0 | CUDA |
| 丂 | ||
| Electronic structure of materials | ||
| LAMMPS | 3.2 | CUDA |
| 丂 | ||
| Molecular dynamics | ||
| Denovo | 3.3 | CUDA |
| 丂 | ||
| 3D neutron transport for nuclear reactors | ||
| Chroma | 6.1 | CUDA |
| 丂 | ||
| Lattice quantum chromodynamics |
丂S3D傗NAMD偺傛偆偵1.4攞偲偄偆傕偺偐傜丆Chroma偺6.1攞傑偱暆偑偁傝傑偡偑丆偄偢傟傕GPU傪晅偗偨曽偑懍偔側偭偰偄傑偡丅Intellagos僠僢僾偲斾傋傞偲丆NVIDIA偺M2090偺徚旓揹椡偼2攞掱搙偱偡偑丆CPU埲奜偺徚旓揹椡偑偁傞偺偱丆惈擻岦忋偑1.4攞側傜僄僱儖僊乕岠棪偼夵慞偝傟偰偄傞偲巚傢傟傑偡丅
丂傑偨丆TitanDev僔僗僥儉偱偼M2090偱偡偑丆杮斣偺Titan偱偼Kepler儀乕僗偺K20偵側傞偺偱丆惈擻岦忋偼峏偵戝偒偔側傞偲梊憐偝傟傑偡丅
丂戝晹暘偺傾僾儕偼CUDA偱彂偒捈偝傟偰偄傑偡偑丆S3D偼OpenACC傪巊偄丆僜乕僗偵僨傿儗僋僥傿僽偺捛壛偲偄偆斾妑揑庤娫偺彮側偄曽朄偱嶌傜傟偰偄傑偡丅傑偨丆CAM-SE傕Fortran僜乕僗傪PGI僐儞僷僀儔偱僐儞僷僀儖偲偄偆偙偲偱丆偙傟傕庤娫偺彮側偄堏怉偲巚傢傟傑偡丅
俀丏嫄戝僗僷僐儞偼昁梫偐丠
丂丂2012擭7寧19擔偺HPCWire偑乭Too Big to FLOP乭偲戣偡傞婰帠傪嵹偣偰偄傑偡丅
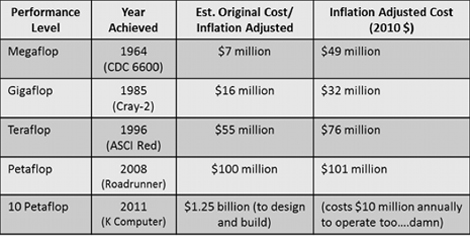
丂丂師偺丆Top500 1埵偺儅僔儞偺僀儞僼儗棪挷惍嵪傒偺悇應僐僗僩偺昞偐傜丆
丂丂
丂丂偙傟傜偺僔僗僥儉偺僐僗僩傪僾儘僢僩偟偨偺偑師偺恾偱偡丅偙偙偵偼$210M乣230M偲悇掕偝傟傞Sequoia傕僾儘僢僩偝傟偰偄傑偡丅偙傟傜偺慡晹偺僔僗僥儉傪峫椂偟偨僐僗僩孹岦傪帵偡偺偑愒偺慄偱丆妱崅偺CDC600偲K Computer傪彍偄偨偺偑惵偺慄偱偡丅
丂丂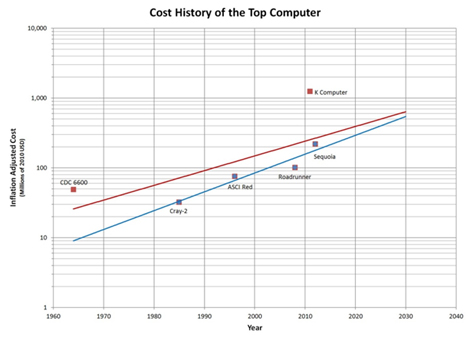
丂丂偦偟偰丆偙偺孹岦傪墑挿偡傞偲2030擭偺1埵偺僔僗僥儉偼$0.5B偲偄偆嫄妟偵側傞偲梊憐偝傟傑偡丅側偍丆K Computer偺$1.25B偼僴乕僪偲僐儞僷僀儔丆OS側偳偺奐敪旓偲恄屗偺僙儞僞乕偺寶暔傪娷傫偩妟偱丆僴乕僪僂僃傾偺挷払梊嶼偼600壄墌掱搙偺敜偱偡丅偦傟偱傕80墌/$偱姺嶼偡傞偲$750M偲側傝傑偡丅
丂丂偟偐偟丆偙傟傜偺嫄戝僗僷僐儞傪娵乆愯桳偟偰巊偆偺偼Top500LINPACK偺應掕偔傜偄偱丆捠忢偺巊梡忬嫷偱偼丆僔僗僥儉傪暘妱偟偰丆偦傟偧傟偺儐乕僓偼傕偭偲彫偝側儅僔儞傪巊偭偰偄傞丅偦偟偰丆儐乕僓偼戝偒側寁嶼儕僜乕僗偑梌偊傜傟傟偽丆偦傟傪巊偆偑丆尰嵼丆庤偵擖傞儕僜乕僗偱偼尋媶偑偱偒側偄偲晄枮傪帩偭偰偄傞偲偄偆忬懺偱傕側偄丅
丂丂偟偨偑偭偰丆崅壙側嫄戝儅僔儞傪嶌傞昁梫偑偁傞偺偐偲偄偆寽擮傪昞柧偟偰偄傑偡丅
丂丂偙傟偼堦棟偁傞偺偱偡偑丆尰戙偺嫄戝儅僔儞偼僋儔僗僞宆偱丆嫄戝偵偡傞偨傔偺僆乕僶僿僢僪偼僀儞僞僐僱僋僩偱偡丅嫗傗BG/Q傪尒偰傕丆僐僗僩偵僀儞僞僐僱僋僩偺愯傔傞妱崌偼傑偁丆2妱掱搙偱丆3妱偼挻偊側偄偲巚偄傑偡丅偦偟偰丆1/16偺惈擻偺儅僔儞傪16戜嶌傞応崌傕丆偙偺僀儞僞僐僱僋僩偑晄梫偵側傞傢偗偱偼側偔丆摨掱搙偺僐僗僩壔丆庒姳丆僗僀僢僠偑彫偝偔側偭偰埨偔側傞掱搙偱丆Flops偁偨傝偺扨壙偑戝偒偔壓偑傞偲偼峫偊擄偄偲巚偄傑偡丅
丂丂偦傟側傜偽丆捠忢偼墻偱嬫愗偭偰彫偝側嵗晘偺廤崌偲偟偰巊偆偗偳丆昁梫側傜丆墻傪庢傝暐偭偰戝峀娫偵傕偱偒傞偲偄偆曽偑丆桳梡惈偑崅偄偲巚偄傑偡丅幚嵺丆椃娰偺戝峀娫傗丆儂僥儖偺儃乕儖儖乕儉偼巇愗傝偺庢傝奜偟偑偱偒傑偡丅
丂丂堦曽丆嫄戝僔僗僥儉傪嶌傞偲側傞偲丆徚旓揹椡傗怣棅搙乮暯嬒屘忈娫妘乯偑戝偒側栤戣偲側傝丆揹椡嶍尭丆怣棅搙岦忋側偳偺媄弍偺奐敪偑恑傒傑偡丅偙傟偑1/16偺婯柾偺僔僗僥儉偱椙偄偲側傞偲丆尰忬偺媄弍傪彮偟夵椙偡傟偽嵪傓偲偄偆偙偲偱丆恑曕偺僗僺乕僪偑撦傞偺偱偼側偄偐偲寽擮偝傟傑偡丅
丂丂妋偐偵$500M偲偄偆梊嶼偺妉摼偼擄偟偄偺偱偡偑丆1/16偺婯柾偱$30M偺儅僔儞側傜16戜偺梊嶼偑庢傟傞偲偄偆榖偱傕側偄偲巚偄傑偡丅
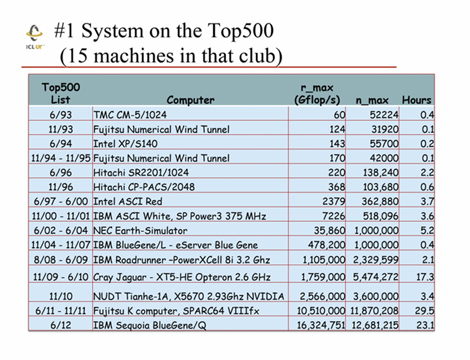
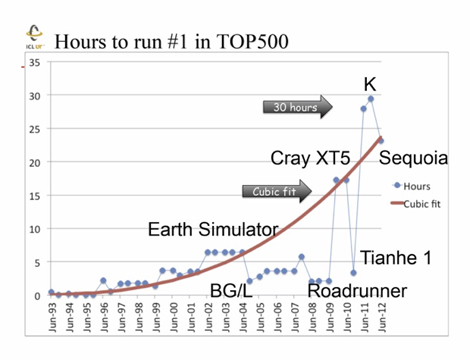
丂丂怣棅搙偵娭偟偰偼丆夁嫀偺1埵儅僔儞偺LINPACK偺幚峴帪娫偺昞偲丆偦偙偐傜偺孹岦偺僌儔僼傪嵹偣偰偄傑偡丅
丂丂LINPACK偼楢棫1師曽掱幃傪夝偔偲偄偆栤戣偱偡偑丆曽掱幃偺枹抦悢偺悢偺3忔偵斾椺偟偰寁嶼検偑憹偊傑偡丅堦曽丆儊儌儕偺R/W偼2忔偺憹壛側偺偱丆枹抦悢傪懡偔偟偨曽偑儊儌儕傾僋僙僗斾棪偑尭傝丆墘嶼惈擻偑弌偣傑偡丅偦偺偨傔丆帩偰傞儊僀儞儊儌儕傪僼儖偵巊偭偰枹抦悢偺懡偄嫄戝栤戣傪夝偔偲偄偆偙偲偵側傝傑偡丅僗僷僐儞偺儊儌儕検偼僺乕僋Flops斾椺傎偳偼憹偊側偄孹岦偵偁傝傑偡偑丆偦傟偱傕1忔偺堘偄偑偁傞偺偱寁嶼検偑憹偊丆LINPACK偺幚峴帪娫偑挿偔側傞偲偄偆孹岦偵偁傝傑偡丅
丂偦偟偰丆偙偺孹岦傪墑挿偡傞偲丆ExaFlops儅僔儞偱偼5.8擔偐偐傞偲梊應偟偰偄傑偡丅LINPACK偺應掕偱偼丆怓乆偲僠儏乕僯儞僌僷儔儊僞傪曄偊偰應掕偟偰丆Top500偵搊榐偡傞儀僗僩偺應掕抣傪摼傞偺偱丆壖偵10夞應掕偲偟偰傕丆堦夞偵6擔偱偼丆60擔儅僔儞慡懱傪愯桳偡傞偙偲偵側傝傑偡丅傑偨丆應掕拞偵屘忈偡傞偲丆傗傝捈偟偵側傞偺偱丆峏偵儔儞偺夞悢偑憹偊傑偡丅偲偄偆偙偲偱丆1夞偱5.8擔傕偐偐傞應掕偼丆帠幚忋丆傗傟傑偣傫丅
丂Top500偺庡嵜幰懁傕丆栤戣偱偁傞偙偲偼廫暘擣幆偟偰偍傝丆6寧偺ISC12偱丆Dongarra愭惗偼Reduced Linpack to Keep the Run Time Manageable for Future TOP500 Lists偲偄偆採埬傪峴偭偰偄傑偡丅
俁丏朰傟嫀傜傟偨CPU崟楌巎
丂丂偲戣偡傞杮偑丆2012擭7寧10擔偵傾僗僉乕丒儊僨傿傾儚乕僋僗偐傜敪攧偝傟傑偟偨丅挊幰偼僥僋僯僇儖儔僀僞乕偺戝尨梇夘偝傫偱偡丅巹傕憗懍丆傾儅僝儞偱僆乕僟乕偟偰攦偄傑偟偨丅
丂丂崟楌巎CPU偼丆媄弍揑丆偁傞偄偼彜嬈揑偵幐攕偱丆夛幮偵傕戝偒側懝幐傪梌偊丆偦偺夛幮偺楌巎偱傕枙嶦偝傟傛偆偲偟偰偄傞CPU偲偄偆偙偲偱丆懠幮偵傕偨偔偝傫偁傞偺偱偡偑丆偙偺杮偱偼Intel偲AMD偺僾儘僙僒傪拞怱偵庢傝忋偘偰偄傑偡丅
丂丂Intel偱偼Timna丆iAPX432丆i860丆i960丆Prescott乣Tejas丆Xscale丆Merced丆AMD偱偼Am29000丆K6-嘨丆K8丆弶戙K10丆偦偟偰慻傒崬傒偺Elan偲Geode偑崟楌巎偲偟偰庢傝忋偘傜傟偰偄傑偡丅峏偵丆Motorola偺MC88100/88110偑捛壛偲偟偰庢傝忋偘傜傟偰偄傑偡丅
丂丂偙傟傜偺CPU偼奐敪偑戝偒偔抶墑偟偨傝丆徚旓揹椡偑戝偒偐偭偨傝丆惈擻偑弌側偄偲偄偆媄弍揑側幐攕偲偄偆傕偺傕偁傝傑偡偑丆Xscale偺傛偆偵媄弍揑偵偼惉岟偲尵偊傞偺偵丆懠幮偵攧媝偝傟偰偟傑偭偨偲偄偆崟楌巎傕偁傝傑偡丅偙偺傛偆側幐攕傪妛傇偙偲偼丆惉岟椺傪妛傇埲忋偵壙抣偑偁傞偺偱偼側偄偐偲巚偄傑偡丅偨偩偟丆戝尨偝傫偺幐攕偺尨場偺婰弎偼晹奜幰偺尒曽偱丆摉帠幰偺尒曽偲堦抳偡傞偐偳偆偐偼暘偐傝傑偣傫丅
丂丂屄恖揑偵偼丆晜摦彫悢揰彍嶼偺僶僌偱丆$500M偲偄偆儅僀僋儘僾儘僙僒巎忋嵟戝偺儕僐乕儖傪弌偟偨Pentium 嘨側偳傕崟楌巎偵擖偭偰傕椙偐偭偨偺偱偼側偄偐偲巚偄傑偟偨丅
丂丂偙傟傜偺崟楌巎偺僾儘僙僒偱傕丆愝寁偵実傢偭偨僄儞僕僯傾偼堦惗寽柦搘椡偟偰偄偨偙偲偼娫堘偄側偔丆彜嬈揑偵偼幐攕偲偼尵偊丆偙傟傜偺CPU偺懚嵼偑楌巎偐傜枙嶦偝傟偰偟傑偆偺偼斶偟偄偙偲偱偡丅戝尨偝傫傕偁偲偑偒偵彂偄偰偍傜傟傑偡偑丆偙傟傜偺CPU偺曟旇柫偲偟偰傕堄媊偺偁傞杮偩偲巚偄傑偡丅
丂丂偟偐偟丆偙偺杮偵庢傝忋偘傜傟偨僾儘僙僒傪抦傜側偄偲丆偁傑傝嫽枴偑桸偐側偄偲巚傢傟傞偺偱丆傗偼傝丆堦晹偺撉幰岦偗偐偲巚偄傑偡丅
丂丂
丂
丂